

Recherche d’information : la grande recherche vers la connaissance

Nous vivons dans une société de l’information. Les données, les faits et les connaissances sont beaucoup plus importants qu’il y a un demi-siècle. En même temps, grâce à Internet, il y a de plus en plus d’informations disponibles. Mais celles-ci doivent aussi être récupérées, et c’est ici qu’interviennent les moteurs de recherche. Mais comment obtiennent-ils à leur tour les données qu’ils produisent ? C’est ce que l’on appelle la recherche d’informations. La recherche d’informations, également appelée récupération d’informations, est une discipline distincte de l’informatique et des sciences de l’information, et revêt une grande importance pour les moteurs de recherche. À l’aide de systèmes de recherche d’information assez complexes, ils identifient les intentions derrière certains termes de recherche et localisent les données pertinentes dans les requêtes de recherche.
L’histoire de la recherche d’informations
La recherche d’information consiste à rendre accessibles les connaissances existantes. Cela n’a pas seulement été le cas depuis le début de l’ère numérique. Vannevar Bush est l’un des premiers scientifiques à réfléchir sérieusement à la manière dont l’humanité peut rendre ses connaissances concentrées plus facilement accessibles face à un monde de plus en plus confus. En 1945, il a écrit l’article révolutionnaire As We May Think, dans lequel il présente une vision de l’avenir de la collecte et de l’organisation de l’information.
Bush voyait dans les sciences le problème suivant : les experts deviennent de plus en plus spécialisés et ont donc besoin de plus en plus d’informations, ce qui, précisément à cause de la différenciation, est de plus en plus difficile à trouver. Il est à noter que c’était à une époque où les bibliothèques étaient encore organisées avec des blocs-notes analogiques et des grands catalogues. Une recherche par mot-clé n’était possible que si un bibliothécaire consciencieux s’était donné la peine d’indexer toutes les œuvres manuellement. M. Bush a vu dans les progrès techniques de l’époque, comme les microfilms, une occasion de rendre l’information plus facilement accessible. Sa propre vision s’appelait Memex, une machine aussi grande qu’un bureau, qui devait servir de réservoir de connaissances et d’appareil de recherche. Memex n’a jamais été construit, mais la technologie qui consiste à faire passer l’utilisateur d’un article à l’autre, peut être considérée comme un précurseur de l’hypertexte.
Dans les années 1950, l’informaticien Hans Peter Luhn s’est particulièrement intéressé aux tâches d’acquisition de l’information et a développé des techniques qui sont toujours d’actualité : en effet, c’est sur ses recherches que sont basés le traitement de texte intégral, l’indexation automatique et le traitement sélectif de l’information (SDI). Ces méthodes ont été d’une grande importance pour le développement d’Internet car il est indispensable, dans le flot d’informations du Web, d’utiliser des systèmes de recherche d’informations. Sinon, nous n’obtiendrions jamais les réponses dont nous avons besoin.
Recherche d’information : définition
L’objectif de la recherche d’information (Information retrieval ou IR en anglais) est de rendre les données stockées automatiquement consultables. Contrairement au Data-Mining, qui sert à extraire des structures à partir d’ensembles de données, l’IR s’intéresse au filtrage de certaines informations d’un ensemble de données. Le domaine d’application typique est un moteur de recherche sur Internet. Les systèmes de recherche d’information résolvent ici deux problèmes principaux :
- Flou : les requêtes des utilisateurs sont souvent imprécises, et le terme de recherche saisi laisse place à l’interprétation. Si, par exemple, vous recherchez le terme « banque », vous pouvez avoir besoin d’informations sur les opérations bancaires en général ou des indications pour vous rendre à l’institution financière la plus proche. Le problème est exacerbé lorsque les utilisateurs eux-mêmes ne savent pas encore exactement quel type d’information ils veulent trouver.
- Incertitude : le contenu des informations stockées peut ne pas être suffisamment connu du système. Il en résulte des résultats incorrects. C’est le cas, par exemple, des homonymes ou des termes polysémiques. Ainsi, un utilisateur qui tape « jumelles » peut aussi bien s’intéresser à un instrument d’observation qu’à la gémellité.
En outre, le système de recherche d’information devrait également évaluer l’information afin de fournir à l’utilisateur une séquence de données. Le premier résultat devrait donc idéalement fournir la meilleure réponse à la question de l’utilisateur.
Présentation de différents modèles
Il existe différents modèles de recherche d’information. Ils ne s’annulent pas nécessairement entre eux, mais peuvent au contraire être combinés. Il existe aujourd’hui de nombreux modèles de ce type, dont certains ne diffèrent que par les détails. On peut toutefois les diviser en trois grandes catégories :
- Modèles théoriques de quantité : les relations de similitude sont déterminées par des opérations de quantité (modèle booléen).
- Modèles algébriques : les similarités sont déterminées par paires ; les documents et les requêtes de recherche peuvent être affichés sous forme de vecteurs, matrices ou tuples (modèle vectoriel spatial).
- Modèles probabilistes : ces modèles établissent des relations de similarité en considérant les ensembles de données comme des expériences aléatoires à plusieurs degrés.
Dans ce qui suit, nous présentons les trois modèles archétypaux de ces catégories. Les autres modèles existants sont principalement des formes mixtes des trois types. Ainsi, le modèle booléen étendu possède les propriétés des modèles théoriques et algébriques.
Modèle booléen
Les moteurs de recherche les plus connus sur le Web sont basés sur le principe booléen. Ce sont des liens logiques qui permettent aux utilisateurs d’affiner la recherche. Avec AND, OR ou NOT (AND, OR, OR, NOT) ou les symboles correspondants ∧, ∨ ou ¬ une requête peut être spécifiée, par exemple si les deux termes doivent apparaître dans le résultat, ou si le contenu avec un certain terme doit être masqué. Ce principe est également suivi par les opérateurs de Google. L’inconvénient de ce système est qu’il ne prévoit aucun classement des résultats. Un ordre selon l’utilité a du sens, mais la méthode fournit un ordre aléatoire.
Modèle spatial vectoriel
Dans une approche mathématique, le contenu peut également être représenté sous forme de vecteurs. Dans le modèle vectoriel spatial, les termes sont cartographiés comme axes de coordonnées. Les documents et les requêtes de recherche reçoivent des valeurs spécifiques par rapport au terme et peuvent donc être affichés sous forme de points ou de vecteurs dans un espace vectoriel. Les deux vecteurs sont ensuite comparés l’un à l’autre. Le vecteur (c’est-à-dire le contenu) le plus similaire à celui de la requête de recherche doit apparaître en premier dans le classement des résultats. L’inconvénient ici, c’est qu’aucun terme ne peut être exclu sans opérateurs booléens.
Modèle probabiliste
Le modèle probabiliste est basé sur la théorie des probabilités. Une valeur de probabilité est attribuée à chaque contenu. Les résultats sont triés en fonction de la probabilité avec laquelle ils correspondent à l’intention de recherche. Le modèle utilise ce que l’on appelle le retour d’information sur la pertinence pour déterminer dans quelle mesure les chances qu’un contenu donné réponde aux souhaits de l’utilisateur sont élevées. Par exemple, on demande aux utilisateurs d’évaluer les résultats manuellement. Dans la requête identique suivante, le modèle affiche une liste de résultats différente (et peut-être meilleure). L’inconvénient de cette procédure est qu’elle repose sur deux conditions qui ne sont pas certaines : d’une part, le modèle suppose que les utilisateurs sont disposés à participer au système grâce à leur rétroaction. D’autre part, la théorie suppose que les utilisateurs voient les résultats indépendamment les uns des autres, c’est-à-dire qu’ils évaluent chaque contenu comme s’il s’agissait du premier qu’ils lisent en relation avec la requête de recherche. Dans la pratique, cependant, les chercheurs évaluent toujours l’utilité de l’information en fonction du contenu qui a déjà été consulté.
Fonctions de recherche d’information
La recherche d’informations utilise différentes méthodes et techniques de travail, indépendamment des modèles. Leur but est toujours de permettre à l’utilisateur de trouver plus facilement des informations et d’obtenir des résultats plus pertinents.
Term Frequency-Inverse Document Frequency
L’importance d’un terme pour une requête de recherche est calculée par la combinaison de la fréquence d’occurrence des termes et de la fréquence inverse du document. La valeur est abrégée en TF-IDF.
- Term Frequency : la densité des termes de recherche spécifie la fréquence à laquelle un terme apparaît dans un document. Cependant, la fréquence pure de l’occurrence ne peut pas être une indication unique de la pertinence du texte. En effet, le terme de recherche peut apparaître plus fréquemment dans un document long que dans un document court. Par conséquent, la fréquence doit être considérée par rapport à la taille d’un document. Pour ce faire, la fréquence du terme de recherche est divisée par la fréquence du mot de fréquence le plus élevé (par exemple « et ») :


- Inverse Document Frequency : pour IDF, on ne considère pas seulement un seul document, mais un corpus de textes complet. Les mots que l’on ne trouve que dans très peu de documents, mais aussi très fréquemment, sont plus pertinents que ceux que l’on trouve dans presque tous les textes. Par exemple, la « Inverse Document Frequency » a une valeur beaucoup plus élevée que « et ».
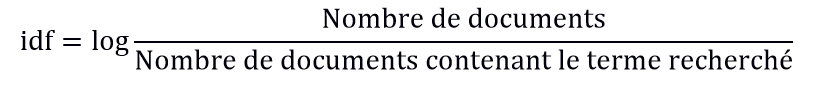

En combinant les deux tests, les systèmes de recherche d’information peuvent donner de meilleurs résultats que s’ils étaient utilisés seuls : si seul le Term Frequency était important, la requête de recherche « Des racines et des ailes » estimerait fortement les documents dans lesquels les mots « des », et « et » apparaissent fréquemment. Mais ce n’est évidemment pas très utile. Si, par contre, on consulte la fréquence des documents inverses, les termes « diffusion », « émission » et « racines » deviennent beaucoup plus pertinents pour la recherche, et sont reconnus comme les termes de recherche réels.
Modification de la requête
Les utilisateurs eux-mêmes constituent un problème majeur dans l’obtention de l’information : par des demandes trop imprécises, voire inexactes, ils reçoivent en effet des informations erronées ou insuffisantes. Pour éviter cela, les scientifiques de l’information ont introduit la modification de requête (query modification en anglais). Le système modifie automatiquement la requête de recherche saisie. Par exemple, on utilise des synonymes qui donnent de meilleurs résultats. Le système utilise, entre autres, des thésaurus et des commentaires des utilisateurs dans ce but. Afin de ne pas dépendre de la coopération de l’utilisateur, on peut également utiliser une sorte de feedback. Avec cette méthode, le système lit les termes apparentés dans les meilleurs résultats de recherche et les évalue comme pertinents pour la recherche correspondante. Ces techniques peuvent être utilisées, entre autres, pour étendre ou améliorer les demandes :
- Élimination des mots vides : les mots vides sont des expressions qui ne contribuent pas ou seulement de manière insignifiante au contenu du texte. Il est utile de ne pas considérer des mots tels que « et » ou tous les articles comme représentatifs du contenu du document.
- Identification des groupes de mots multiples : les groupes de mots doivent être reconnus comme tels. Cette identification garantit que le moteur de recherche considère également les parties de mots composés comme pertinentes.
- Réduction de la forme de base et de la forme racine : pour une recherche plus efficace, les mots doivent être réduits à leur forme racine. Sinon, les formes de flexion d’un mot n’apparaîtraient pas correctement dans les résultats de recherche.
- Thésaurus : outre les termes figurant dans le document correspondant, un système de recherche d’information devrait également considérer les synonymes du mot comme pertinents. C’est la seule façon de s’assurer que les utilisateurs trouvent ce qu’ils cherchent.
Précision et rappel
L’efficacité d’un système de recherche d’information est généralement calculée à l’aide des facteurs rappel (recall) et précision. Les deux sont affichés sous forme de quotients.
- Rappel : dans quelle mesure les résultats de la recherche sont-ils complets ? Pour répondre à cette question, le nombre de documents pertinents trouvés est comparé au nombre de documents non trouvés et pertinents. Le quotient indique la probabilité qu’un document pertinent soit trouvé :
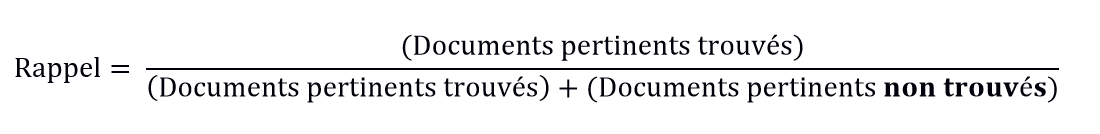
- Précision : quel est le résultat exact de la recherche ? Pour répondre à cette question, le nombre de documents trouvés et pertinents est comparé au nombre de documents trouvés et non pertinents. Le quotient indique donc la probabilité qu’un document trouvé soit pertinent :
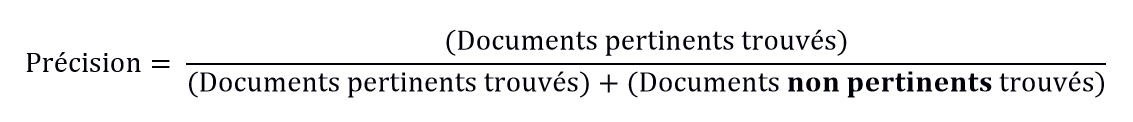
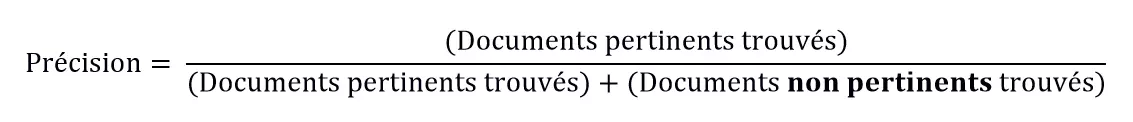
Les deux valeurs se situent fondamentalement entre 0 et 1, où 1 serait une valeur parfaite. De plus, les résultats parfaits dans les deux quotients s’excluent mutuellement dans la pratique. Ceux qui augmentent l’exhaustivité du résultat de la recherche le font au détriment de l’exactitude et inversement. Une autre valeur qui peut être calculée est le taux de retombées (c’est-à-dire le taux d’échec) : ce quotient représente le taux de faux positifs ; il est déterminé à partir du rapport entre les documents non pertinents trouvés et le contenu non pertinent qui n’a pas été trouvé. Le rappel et la précision peuvent être affichés dans un diagramme d’axes dans lequel chacune des deux valeurs occupe un axe.
Recherche d’information : exemple d’une recherche
Chaque moteur de recherche sur Internet est basé sur la recherche d’informations. Google, Bing et Yahoo seraient donc des exemples éminents de collecte d’informations assistée par ordinateur. Toutefois, pour montrer comment fonctionne l’IR dans la pratique, il est plus judicieux de prendre un exemple plus simple du vôtre. Nous supposons un moteur de recherche dans une (très petite) bibliothèque de livres pour enfants. Tous les livres contiennent des animaux, mais nous souhaitons seulement trouver des livres dans lesquels les éléphants et les girafes jouent un rôle, pas les crocodiles. Une requête de recherche utilisant la méthode booléenne ressemblerait donc à ceci : Éléphant ET Girafe PAS Crocodile. Le résultat de la recherche ne peut toujours être que 1 ou 0 : le terme est-il présent ou non ?
| Je mangerais bien un enfant | Petite girafe est surprise | L’affaire de l’éléphant en pantoufles | Elmer | Moi pas, moi aussi | |
| Éléphant | 0 | 1 | 1 | 1 | 1 |
| Girafe | 0 | 1 | 1 | 1 | 0 |
| Crocodile | 1 | 0 | 0 | 1 | 0 |
| Chien | 0 | 0 | 0 | 0 | 1 |
| Lion | 0 | 0 | 0 | 1 | 0 |
| Tigre | 0 | 0 | 0 | 1 | 0 |
Le résultat de la recherche serait donc Petite girafe est surprise et L’affaire de l’éléphant en pantoufles. Toutefois, cela ne signifie pas encore que les résultats sont pondérés. Quel livre est plus sur les éléphants et les girafes ? Pour répondre à cette question, le système peut déterminer la fréquence du terme et la fréquence inverse. (Les valeurs ci-dessous sont données à titre indicatif).


Ainsi, Petite girafe est surprise est probablement mieux adapté à la recherche d’un texte avec des girafes et des éléphants que L’affaire de l’éléphant en pantoufles, et devrait donc apparaître en premier dans les résultats de recherche. La méthode que nous avons utilisée ici ne fonctionne que si les termes de recherche sont spécifiés (indexation contrôlée). Ceci peut être le cas, par exemple, dans les bases de données spécialisées où les utilisateurs sont formés à l’utilisation du masque de recherche. Dans notre exemple, une modification de la requête serait utile : outre « éléphant », une recherche de « pachydermes » ainsi que des variantes grammaticales de ces mots donneraient des résultats positifs.
Outre Google, il existe de nombreux autres moteurs de recherche. Les alternatives à Google sont par exemple souvent plus attentives à la protection des données.